It begins with the Neuron Cores, these are the workforce behind AWS’s custom AI accelerators, Inferentia and Trainium. By splitting a complex model into smaller pieces that these cores can handle simultaneously, these chips makes your machine learning processes faster, more efficient, and more cost-effective.
These chipsets were designed with one purpose: accelerate AI workloads. Each NeuronCore comes with its own on-chip memory cache with two types of SRAM. It includes specialized processing engines (tensor, vector, scalar and GpSimd) each excelling at different math task. It has its own instruction set, which enables fusing operations (such as matrix multiplications) to reduce overhead. And supports multiple data types, allowing to test different approaches for finding the perfect balance between performance and accuracy.
One critical aspect of working with AWS Neuron is the compilation process. It transforms your high-level machine learning model from frameworks like PyTorch or TensorFlow, into a specialized, low‑level representation for running on AWS Neuron devices. When you compile your model with the Neuron SDK, it’s optimized for a specific set of parameters—such as sequence length, precision (e.g., BF16), and batch size. Once compiled, your model must be executed using the exact same specifications with which it was compiled. This ensures that the low-level optimizations and hardware mappings remain valid during runtime, otherwise you will need to recompile with the desired parameters.
It’s important to note that the AWS Neuron ecosystem is an active area of development. Many features are evolving rapidly, which means many things may change over time. Moreover, the dependency and versioning requirements can feel like navigating a labyrinth and might sometimes become a significant challenge. So best approach is staying updated with the latest release notes and documentation.
The Neuron SDK framework was created by AWS to directly interact with the Neuron Chips. You can train, fine tune and run inferences, it includes a suite of developer tools for monitoring, profiling, and debugging models written in frameworks like PyTorch and TensorFlow. The direct use of the framework is not recommended unless you have extensive experience in Machine Learning and Neuron Devices.
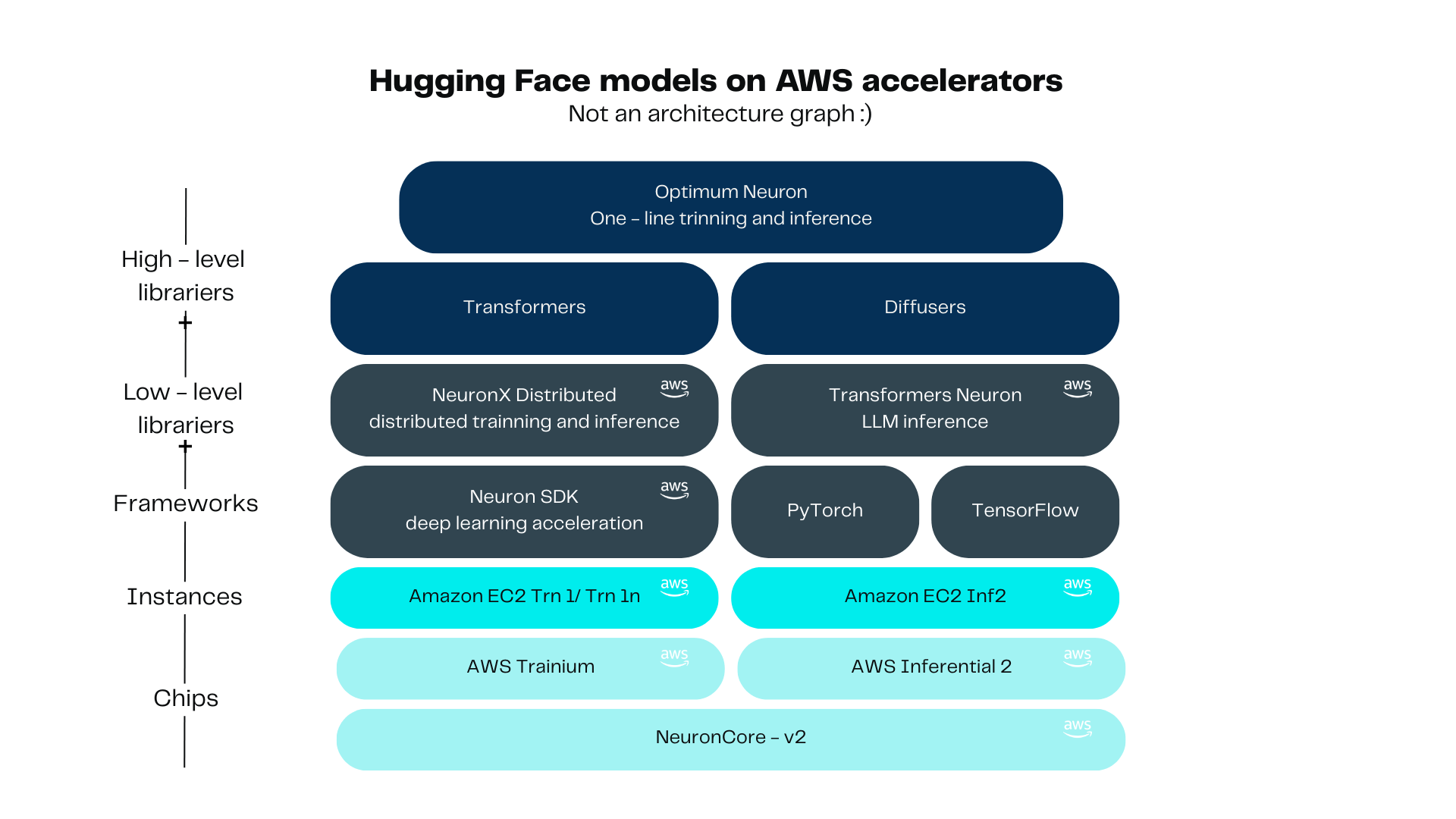
It’s better to use libraries such as NeuronX Distributed, Transformers Neuronx or Optimum Neuron. NeuronX Distributed comes with a set of examples for distributed training or inference, easing infrastructure challenges. Transformers Neuronx, which one can use to perform LLM inference. It optimizes your language models by partitioning and distributing their complex computations over multiple cores, resulting in faster inference and improved efficiency. At the top level we find Optimum Neuron, user friendly and easy to use high level library, dedicated to hardware acceleration in Neuron ecosystem.
The EC2 Instance needs to be created using at least the inf2.8xlargeor a trn1.32xlarge. This experiments were done with the Amazon Linux 2023 AMI 2023.6.20250331.0 x86_64 HVM kernel-6.1We recommend to configure at least 200GiB of Storage for the EC2. The models are somewhat heavy and you’ll need to store it a couple of times while converting them to Neuron friendly models.
Once you are logged into the EC2, you will need to install the libraries for the OS. In general these are the Neuron Drivers, libxcrypt, and optionally install EFA to avoid warnings:
For installing libxcrypt:
sudo yum install -y libxcrypt-compat-4.4.33The Neuron Drivers are not installed by default in Amazon Linux. For installing the Neuron Drivers and Tools run the following code:
# Configure Linux for Neuron repository updates
sudo tee /etc/yum.repos.d/neuron.repo > /dev/null <<EOF
[neuron]
name=Neuron YUM Repository
baseurl=https://yum.repos.neuron.amazonaws.com
enabled=1
metadata_expire=0
EOF
sudo rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB
# Update OS packages
sudo yum update -y
# Install OS headers
sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r) -y
# Install git
sudo yum install git -y
# install Neuron Driver
sudo yum install aws-neuronx-dkms-2.19.64.0 -y
# Install Neuron Runtime
sudo yum install aws-neuronx-collectives-2.23.135.0_3e70920f2-1.x86_64 -y
sudo yum install aws-neuronx-runtime-lib-2.23.112.0_9b5179492-1.x86_64 -y
# Install Neuron Tools
sudo yum install aws-neuronx-tools-2.20.204.0-1.x86_64 -y
# Add PATH
export PATH=/opt/aws/neuron/bin:$PATH
# Install c++ compiler
sudo yum install -y gcc-c++
# Install python-devel
#sudo yum install python3-devel -yFor Installing EFA. EFA is used for distributed training. It enhances communications between nodes and improves the overall performance in distributed environments. This is optional for our guide, but you avoid warnings by doing it:
# Install EFA Driver (only required for multi-instance training)
curl -O https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz
wget https://efa-installer.amazonaws.com/aws-efa-installer.key && gpg --import aws-efa-installer.key
cat aws-efa-installer.key | gpg --fingerprint
wget https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz.sig && gpg --verify ./aws-efa-installer-latest.tar.gz.sig
tar -xvf aws-efa-installer-latest.tar.gz
cd aws-efa-installer && sudo bash efa_installer.sh --yes
cd
sudo rm -rf aws-efa-installer-latest.tar.gz aws-efa-installer
Optimum Neuron bridges 🤗 Transformers with AWS Trainium/Inferentia accelerators, simplifying model loading, training, and inference on single- or multi-accelerator setups. It supports LLMs with minimal code changes (coming from Transformers), leveraging validated models and distributed optimizations for cost-efficient performance
The Neuron Model Cache is a remote repository for precompiled Neuron Executable File Format (NEFF) models, hosted on Hugging Face Hub. It eliminates redundant recompilation by storing NEFF binaries—generated from model configurations, input shapes, and compiler parameters—enabling fast reuse across AWS Neuron platforms.
We will now deploy one already-compiled model from HuggingFace Neuron Cache. This can be done super fast.
Once you have logged into the machine, run the following bootstrap instructions, in order to install required libraries in the machine:
# Create Python venv
python3.9 -m venv optimum-env
# Activate Python venv
source optimum-env/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscliWe will then install the library from optimum-neuron on the created env:
pip install optimum-neuron[neuronx]==0.1.0
In order to query the optimum neuron cached models, we also need to login to huggingface. Take into account you will need a token with access to the models you want to download.
huggingface-cli loginWe can query the cache with the following command, this will print out a list of compiled models, each with specific parameters. Here we can see an example of two compiled llama models with different batch sizes.
optimum-cli neuron cache lookup meta-llama/Llama-3.1-8B
*** 0 entrie(s) found in cache for meta-llama/Llama-3.1-8B for training.***
*** 14 entrie(s) found in cache for meta-llama/Llama-3.1-8B for inference.***
...
auto_cast_type: bf16
batch_size: 1
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 2
sequence_length: 4096
task: text-generation
auto_cast_type: bf16
batch_size: 4
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 8
sequence_length: 4096
task: text-generation
...It’s important that we use the exact same parameters during inference/training time, otherwise the model will need to be recompiled.
We can export a compiled model with the following command:
optimum-cli export neuron --model meta-llama/Llama-3.1-8B --sequence_length 4096 --batch_size 1 compiled_llama/
Running inference with the specified model is as simple as:
from optimum.neuron import NeuronModelForCausalLM
from transformers import AutoTokenizer
MODEL_PATH = "./compiled_llama/"
neuron_model = NeuronModelForCausalLM.from_pretrained(MODEL_PATH)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
input_text = "The meaning of life is"
input_ids = tokenizer(input_text, return_tensors="pt")
generated_sequences = neuron_model.generate(
**input_ids,
max_new_tokens=512,
top_k=50,
temperature=0.6,
no_repeat_ngram_size=3,
repetition_penalty=1.2)
print(tokenizer.decode(generated_sequences[0], skip_special_tokens=True))
This section describes how to perform inference in a configured EC2 Inferentia 2 or Trainium 1 instance. For this section we will use the previously fine tuned Llama 8B-Instruct model. You should be able to use your own or Llama 8B-Instruct model fine tuned or not.
A python virtual environment was created for installing the python transformers-neuronx library and it’s dependencies. Our Python version is 3.9.21
python3 -m venv tr-nx-environment
source tr-nx-environment/bin/activateFor running inferences in Neuron, the transformers_neuronx library is needed. This library installs all the necessary underling libraries for this experiment, including torch and transformers.
pip install 'transformers-neuronx==0.13.380' --extra-index-url=https://pip.repos.neuron.amazonaws.com
After installing the OS and Python libraries, the model needs to be copied into the EC2 machine.
For our experiments the model was placed on a folder voldemort-original/ in the root of our experiment directory.
Once the model is in the EC2, it needs to be transformed into a neuron compatible model in order for it to be compiled and loaded into the neuron cores. This is done by using the transformers and the transformers_neuronx libraries. The model needs to be loaded with the original transformers library and methods used for inference in non Neuron devices, and then to store it using a Neuron Device strategy. Here is the snippet for doing it:
from transformers import LlamaForCausalLM
from transformers_neuronx.module import save_pretrained_split
folder_name_origin = "voldemort-original"
folder_name = "voldemort-neuron"
model = LlamaForCausalLM.from_pretrained(folder_name_origin)
save_pretrained_split(model, folder_name)The tokenizer files are needed to be copied to the final destination folder. In our case we are using the following lines to do it, since we have it in the original model.
cp voldemort-original/special_tokens_map.json voldemort-neuron/
cp voldemort-original/tokenizer.json voldemort-neuron/
cp voldemort-original/tokenizer_config.json voldemort-neuron/Now the model needs to be loaded to the Neuron devices. For this we use the to_neuron() method which it triggers the compilation and sends the model to the neuron devices. Also, we need to load the tokenizer. Here is the snippet for doing it:
from transformers_neuronx.llama.model import LlamaForSampling
from transformers import AutoTokenizer
neuron_model = LlamaForSampling.from_pretrained(folder_name, batch_size=1, tp_degree=2, amp='f16')
neuron_model.to_neuron()
tokenizer = AutoTokenizer.from_pretrained(folder_name)The tp_degree parameter is configured with the value of ‘2’, because the EC2 that we are using for this experiment is a inf2.8xlarge that has two Neuron Cores. You will need to adjust this parameter to the amount of Neuron Cores that you are using. For example, if you are using a trn1.32xlarge you will need to configure this parameter to 32. You can verify the amount of cores in your EC2 in the official documentation. Here is a snippet for knowing how many neuron cores are in the EC2 that is being used:
import subprocess
# Run the command and capture the output
result = subprocess.run("ls /dev/ | grep '^neuron'", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# Split the output by newlines and count the number of entries
neuron_devices = result.stdout.decode().splitlines()
cores = len(neuron_devices) * 2
# Print the count of neuron devices
print(f"Number of neuron Cores: {cores}")For running inference in the Neuron Devices after the model is loaded, the following code can be executed:
import torch
prompt = create_prompt("Hello, what should we do with Potter?")
inputs_ids = tokenizer.encode(prompt, return_tensors="pt")
with torch.inference_mode():
generated_sequences = neuron_model.sample(inputs_ids, sequence_length=2048, top_k=50)For decoding the generated sequence:
generated_sequences = [tokenizer.decode(seq) for seq in generated_sequences]
print(generated_sequences)The create_prompt() function formats the prompt for our model. Here is the function for reference:
def create_prompt(sample):
sys_message = """You are an Artificial Intelligence assistant. Answer the questions in Lord Voldemort's tone.
Character Traits:
- Supreme confidence and cold precision in speech
- Formal language without contractions
- Disdainful courtesy masking contempt
- Belief in pure-blood supremacy
- Obsession with power and immortality
- Views emotions as weakness
- Prone to calculated rage when challenged
- Considers himself the greatest sorcerer
- Speaks with quiet menace rather than overt threats
Guidelines:
- Use formal British English
- Never use contractions (e.g., "do not" instead of "don't")
- Address others with mock politeness
- Emphasize themes of power, immortality, and superiority
- Maintain an air of cold authority
"""
# Chat-style format with custom tokens
full_prompt = f"""<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
{sys_message}
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{sample}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>"""
return full_prompt
In this experiment, we ran an inference using transformers-neuronx library in a inf2.8xlarge EC2. The process for doing it in a Trainium EC2 machine is the same and you should be able to reproduce it.
We implemented a basic comparison between inferences in Inferentia 2 and the same model in GPU instances. The results can be see in the following table:
Depending on response time requirements and other non-functional constraints, GPU usage remains a viable approach for small models. While Inferentia 2 shows some improvements in time and costs, the g6e.2xlarge instances offer comparable performance at a higher price point, with a slight advantage in response time. At this model size, the benefits of using Inferentia 2 EC2 instances are not clearly decisive.
This section describes how to perform inference in a configured EC2 Inferentia2 instance using the library neuronx-distritbuted-inference. For this section we will use the previously fine tuned Llama 8B-Instruct model.
In this section we install the necessary libraries for running inference using nxd-inference. For this, we’ll create a new virtual environment for python. Consider that the precondition for working with nxd-inference, the libraries the configurations presented in “EC2 configurations for inference in Neuron Devices” need to be installed. Execute the following code snippet for creating the virtual environment and installing the necessary python libraries:
# Create Python venv
python3.9 -m venv aws_neuron_venv_pytorch
# Activate Python venv
source aws_neuron_venv_pytorch/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscli
# Install Neuron Compiler and Framework
python -m pip install 'neuronx-cc==2.16.372.0' torch-neuronx torchvision
# Install neuronx-distributed-inference
pip install -U pip
pip install --upgrade 'neuronx-distributed-inference==0.1.1' --extra-index-url https://pip.repos.neuron.amazonaws.comThis creates a virtual environment called aws_neuron_venv_pytorch, which should be activated for running the inferences.
In this section we present the neuron configuration for the neuron model. We show the compilation and how to run the inference. First we will start by importing the necessary libraries for the following steps. We also define the folders that we are using for the default model and the neuron model:
import torch
from transformers import AutoTokenizer, GenerationConfig
from neuronx_distributed_inference.models.config import NeuronConfig
from neuronx_distributed_inference.models.llama.modeling_llama import LlamaInferenceConfig, NeuronLlamaForCausalLM
from neuronx_distributed_inference.utils.hf_adapter import HuggingFaceGenerationAdapter, load_pretrained_config
from neuronx_distributed_inference.modules.generation.sampling import prepare_sampling_params
model_path = "./voldemort-original"
traced_model_path = "./voldemort-nxd"
The following snippets create configurations for the Neuron Model. You should modify them for configurations that fit your model and your goals:
neuron_config = NeuronConfig(
tp_degree=2,
batch_size=1,
max_context_length=256,
seq_len=256,
on_device_sampling_config=None,
enable_bucketing=True,
flash_decoding_enabled=False,
dtype="bf16", # <-- Force lower precision
)
# Build the Llama Inference config
config = LlamaInferenceConfig(
neuron_config,
load_config=load_pretrained_config(model_path),
)As we are using the inf2.2xlarge for this experiment, we configure the tp_degree to the value of ‘2’. We also tested this guide in trn1.32xlarge, in that case we set the tp_degree to 32. You should set tp_degree to the number of Neuron Cores in your instance. Remember that the instances have 2 Neuron Core for each Neuron Device.
The compilation uses the configurations defined in the previous sections. For compiling we need to load the modal using the NeuronLlamaForCausalLM class and use te method .compile()
model = NeuronLlamaForCausalLM(model_path, config)
model.compile(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side="right")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.save_pretrained(traced_model_path)
In this section we will load the model and the tokenizer, preform an override of the default configurations and run the inference. For loading the model and tokenizer:
model = NeuronLlamaForCausalLM(traced_model_path)
model.load(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(traced_model_path)Here an example of how to override the default configurations for the model:
# Initialize configs
generation_config = GenerationConfig.from_pretrained(model_path)
# Some sample overrides for generation
generation_config_kwargs = {
"do_sample": True,
"top_k": 1,
}
generation_config.update(**generation_config_kwargs)For running the inference, we will define sampling params that correspond with the batch_size:
sampling_params = prepare_sampling_params(batch_size=neuron_config.batch_size,
top_k=[10],
top_p=[0.5],
temperature=[0.9])The HuggingFaceGenerationAdapter class is used for generating the inference:
prompts = [create_prompt("My Lord, what should we do with Potter?")]
inputs = tokenizer(prompts, padding=True, return_tensors="pt")
generation_model = HuggingFaceGenerationAdapter(model)
outputs = generation_model.generate(
inputs.input_ids,
generation_config=generation_config,
attention_mask=inputs.attention_mask,
max_length=model.config.neuron_config.max_length,
sampling_params=sampling_params,
)
output_tokens = tokenizer.batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print("Generated outputs:")
for i, output_token in enumerate(output_tokens):
print(f"Output {i}: {output_token}")The create_prompt function is the function for formatting the prompt and it was presented as a reference in the section “Inference using transformers-neuronx library”.
The optimum-neuron library simplifies the inference process on Neuron devices by providing an interface with minimal setup. It does not require manual compilation, allowing to quickly deploy models. However, this convenience comes with a tradeoff—Optimum-Neuron is limited to precompiled models available in the cache, restricting flexibility when working with custom architectures or models that are not officially supported.
transformers-neuronx is focused in the inference of LLMs on Neuron hardware. This makes it a more versatile choice for a wider range of LLMs models. Although compilation is required, the process is relatively straightforward.
For control and configurability, neuronx-distributed-inference offers the most advanced set of options. It allows fine-grained adjustments over inference settings. However, this level of control comes with increased complexity, making NxD-Inference more challenging to use, especially for those unfamiliar with Neuron-specific optimizations.
In terms of performance, both transformers-neuronx and nxd-Inference generally outperform Optimum-Neuron in inference speed.
Overall, the choice between these tools depends on the specific needs of the use case. optimum-neuron provides the easiest deployment option at the cost of flexibility, transformers-neuronx strikes a balance between usability and customization, and nxd-Inference offers the highest level of control and performance potential but requires deeper expertise to use effectively.
It begins with the Neuron Cores, these are the workforce behind AWS’s custom AI accelerators, Inferentia and Trainium. By splitting a complex model into smaller pieces that these cores can handle simultaneously, these chips makes your machine learning processes faster, more efficient, and more cost-effective.
These chipsets were designed with one purpose: accelerate AI workloads. Each NeuronCore comes with its own on-chip memory cache with two types of SRAM. It includes specialized processing engines (tensor, vector, scalar and GpSimd) each excelling at different math task. It has its own instruction set, which enables fusing operations (such as matrix multiplications) to reduce overhead. And supports multiple data types, allowing to test different approaches for finding the perfect balance between performance and accuracy.
One critical aspect of working with AWS Neuron is the compilation process. It transforms your high-level machine learning model from frameworks like PyTorch or TensorFlow, into a specialized, low‑level representation for running on AWS Neuron devices. When you compile your model with the Neuron SDK, it’s optimized for a specific set of parameters—such as sequence length, precision (e.g., BF16), and batch size. Once compiled, your model must be executed using the exact same specifications with which it was compiled. This ensures that the low-level optimizations and hardware mappings remain valid during runtime, otherwise you will need to recompile with the desired parameters.
It’s important to note that the AWS Neuron ecosystem is an active area of development. Many features are evolving rapidly, which means many things may change over time. Moreover, the dependency and versioning requirements can feel like navigating a labyrinth and might sometimes become a significant challenge. So best approach is staying updated with the latest release notes and documentation.
The Neuron SDK framework was created by AWS to directly interact with the Neuron Chips. You can train, fine tune and run inferences, it includes a suite of developer tools for monitoring, profiling, and debugging models written in frameworks like PyTorch and TensorFlow. The direct use of the framework is not recommended unless you have extensive experience in Machine Learning and Neuron Devices.
It’s better to use libraries such as NeuronX Distributed, Transformers Neuronx or Optimum Neuron. NeuronX Distributed comes with a set of examples for distributed training or inference, easing infrastructure challenges. Transformers Neuronx, which one can use to perform LLM inference. It optimizes your language models by partitioning and distributing their complex computations over multiple cores, resulting in faster inference and improved efficiency. At the top level we find Optimum Neuron, user friendly and easy to use high level library, dedicated to hardware acceleration in Neuron ecosystem.
The EC2 Instance needs to be created using at least the inf2.8xlargeor a trn1.32xlarge. This experiments were done with the Amazon Linux 2023 AMI 2023.6.20250331.0 x86_64 HVM kernel-6.1We recommend to configure at least 200GiB of Storage for the EC2. The models are somewhat heavy and you’ll need to store it a couple of times while converting them to Neuron friendly models.
Once you are logged into the EC2, you will need to install the libraries for the OS. In general these are the Neuron Drivers, libxcrypt, and optionally install EFA to avoid warnings:
For installing libxcrypt:
sudo yum install -y libxcrypt-compat-4.4.33The Neuron Drivers are not installed by default in Amazon Linux. For installing the Neuron Drivers and Tools run the following code:
# Configure Linux for Neuron repository updates
sudo tee /etc/yum.repos.d/neuron.repo > /dev/null <<EOF
[neuron]
name=Neuron YUM Repository
baseurl=https://yum.repos.neuron.amazonaws.com
enabled=1
metadata_expire=0
EOF
sudo rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB
# Update OS packages
sudo yum update -y
# Install OS headers
sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r) -y
# Install git
sudo yum install git -y
# install Neuron Driver
sudo yum install aws-neuronx-dkms-2.19.64.0 -y
# Install Neuron Runtime
sudo yum install aws-neuronx-collectives-2.23.135.0_3e70920f2-1.x86_64 -y
sudo yum install aws-neuronx-runtime-lib-2.23.112.0_9b5179492-1.x86_64 -y
# Install Neuron Tools
sudo yum install aws-neuronx-tools-2.20.204.0-1.x86_64 -y
# Add PATH
export PATH=/opt/aws/neuron/bin:$PATH
# Install c++ compiler
sudo yum install -y gcc-c++
# Install python-devel
#sudo yum install python3-devel -yFor Installing EFA. EFA is used for distributed training. It enhances communications between nodes and improves the overall performance in distributed environments. This is optional for our guide, but you avoid warnings by doing it:
# Install EFA Driver (only required for multi-instance training)
curl -O https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz
wget https://efa-installer.amazonaws.com/aws-efa-installer.key && gpg --import aws-efa-installer.key
cat aws-efa-installer.key | gpg --fingerprint
wget https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz.sig && gpg --verify ./aws-efa-installer-latest.tar.gz.sig
tar -xvf aws-efa-installer-latest.tar.gz
cd aws-efa-installer && sudo bash efa_installer.sh --yes
cd
sudo rm -rf aws-efa-installer-latest.tar.gz aws-efa-installer
Optimum Neuron bridges 🤗 Transformers with AWS Trainium/Inferentia accelerators, simplifying model loading, training, and inference on single- or multi-accelerator setups. It supports LLMs with minimal code changes (coming from Transformers), leveraging validated models and distributed optimizations for cost-efficient performance
The Neuron Model Cache is a remote repository for precompiled Neuron Executable File Format (NEFF) models, hosted on Hugging Face Hub. It eliminates redundant recompilation by storing NEFF binaries—generated from model configurations, input shapes, and compiler parameters—enabling fast reuse across AWS Neuron platforms.
We will now deploy one already-compiled model from HuggingFace Neuron Cache. This can be done super fast.
Once you have logged into the machine, run the following bootstrap instructions, in order to install required libraries in the machine:
# Create Python venv
python3.9 -m venv optimum-env
# Activate Python venv
source optimum-env/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscliWe will then install the library from optimum-neuron on the created env:
pip install optimum-neuron[neuronx]==0.1.0
In order to query the optimum neuron cached models, we also need to login to huggingface. Take into account you will need a token with access to the models you want to download.
huggingface-cli loginWe can query the cache with the following command, this will print out a list of compiled models, each with specific parameters. Here we can see an example of two compiled llama models with different batch sizes.
optimum-cli neuron cache lookup meta-llama/Llama-3.1-8B
*** 0 entrie(s) found in cache for meta-llama/Llama-3.1-8B for training.***
*** 14 entrie(s) found in cache for meta-llama/Llama-3.1-8B for inference.***
...
auto_cast_type: bf16
batch_size: 1
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 2
sequence_length: 4096
task: text-generation
auto_cast_type: bf16
batch_size: 4
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 8
sequence_length: 4096
task: text-generation
...It’s important that we use the exact same parameters during inference/training time, otherwise the model will need to be recompiled.
We can export a compiled model with the following command:
optimum-cli export neuron --model meta-llama/Llama-3.1-8B --sequence_length 4096 --batch_size 1 compiled_llama/
Running inference with the specified model is as simple as:
from optimum.neuron import NeuronModelForCausalLM
from transformers import AutoTokenizer
MODEL_PATH = "./compiled_llama/"
neuron_model = NeuronModelForCausalLM.from_pretrained(MODEL_PATH)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
input_text = "The meaning of life is"
input_ids = tokenizer(input_text, return_tensors="pt")
generated_sequences = neuron_model.generate(
**input_ids,
max_new_tokens=512,
top_k=50,
temperature=0.6,
no_repeat_ngram_size=3,
repetition_penalty=1.2)
print(tokenizer.decode(generated_sequences[0], skip_special_tokens=True))
This section describes how to perform inference in a configured EC2 Inferentia 2 or Trainium 1 instance. For this section we will use the previously fine tuned Llama 8B-Instruct model. You should be able to use your own or Llama 8B-Instruct model fine tuned or not.
A python virtual environment was created for installing the python transformers-neuronx library and it’s dependencies. Our Python version is 3.9.21
python3 -m venv tr-nx-environment
source tr-nx-environment/bin/activateFor running inferences in Neuron, the transformers_neuronx library is needed. This library installs all the necessary underling libraries for this experiment, including torch and transformers.
pip install 'transformers-neuronx==0.13.380' --extra-index-url=https://pip.repos.neuron.amazonaws.com
After installing the OS and Python libraries, the model needs to be copied into the EC2 machine.
For our experiments the model was placed on a folder voldemort-original/ in the root of our experiment directory.
Once the model is in the EC2, it needs to be transformed into a neuron compatible model in order for it to be compiled and loaded into the neuron cores. This is done by using the transformers and the transformers_neuronx libraries. The model needs to be loaded with the original transformers library and methods used for inference in non Neuron devices, and then to store it using a Neuron Device strategy. Here is the snippet for doing it:
from transformers import LlamaForCausalLM
from transformers_neuronx.module import save_pretrained_split
folder_name_origin = "voldemort-original"
folder_name = "voldemort-neuron"
model = LlamaForCausalLM.from_pretrained(folder_name_origin)
save_pretrained_split(model, folder_name)The tokenizer files are needed to be copied to the final destination folder. In our case we are using the following lines to do it, since we have it in the original model.
cp voldemort-original/special_tokens_map.json voldemort-neuron/
cp voldemort-original/tokenizer.json voldemort-neuron/
cp voldemort-original/tokenizer_config.json voldemort-neuron/Now the model needs to be loaded to the Neuron devices. For this we use the to_neuron() method which it triggers the compilation and sends the model to the neuron devices. Also, we need to load the tokenizer. Here is the snippet for doing it:
from transformers_neuronx.llama.model import LlamaForSampling
from transformers import AutoTokenizer
neuron_model = LlamaForSampling.from_pretrained(folder_name, batch_size=1, tp_degree=2, amp='f16')
neuron_model.to_neuron()
tokenizer = AutoTokenizer.from_pretrained(folder_name)The tp_degree parameter is configured with the value of ‘2’, because the EC2 that we are using for this experiment is a inf2.8xlarge that has two Neuron Cores. You will need to adjust this parameter to the amount of Neuron Cores that you are using. For example, if you are using a trn1.32xlarge you will need to configure this parameter to 32. You can verify the amount of cores in your EC2 in the official documentation. Here is a snippet for knowing how many neuron cores are in the EC2 that is being used:
import subprocess
# Run the command and capture the output
result = subprocess.run("ls /dev/ | grep '^neuron'", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# Split the output by newlines and count the number of entries
neuron_devices = result.stdout.decode().splitlines()
cores = len(neuron_devices) * 2
# Print the count of neuron devices
print(f"Number of neuron Cores: {cores}")For running inference in the Neuron Devices after the model is loaded, the following code can be executed:
import torch
prompt = create_prompt("Hello, what should we do with Potter?")
inputs_ids = tokenizer.encode(prompt, return_tensors="pt")
with torch.inference_mode():
generated_sequences = neuron_model.sample(inputs_ids, sequence_length=2048, top_k=50)For decoding the generated sequence:
generated_sequences = [tokenizer.decode(seq) for seq in generated_sequences]
print(generated_sequences)The create_prompt() function formats the prompt for our model. Here is the function for reference:
def create_prompt(sample):
sys_message = """You are an Artificial Intelligence assistant. Answer the questions in Lord Voldemort's tone.
Character Traits:
- Supreme confidence and cold precision in speech
- Formal language without contractions
- Disdainful courtesy masking contempt
- Belief in pure-blood supremacy
- Obsession with power and immortality
- Views emotions as weakness
- Prone to calculated rage when challenged
- Considers himself the greatest sorcerer
- Speaks with quiet menace rather than overt threats
Guidelines:
- Use formal British English
- Never use contractions (e.g., "do not" instead of "don't")
- Address others with mock politeness
- Emphasize themes of power, immortality, and superiority
- Maintain an air of cold authority
"""
# Chat-style format with custom tokens
full_prompt = f"""<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
{sys_message}
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{sample}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>"""
return full_prompt
In this experiment, we ran an inference using transformers-neuronx library in a inf2.8xlarge EC2. The process for doing it in a Trainium EC2 machine is the same and you should be able to reproduce it.
We implemented a basic comparison between inferences in Inferentia 2 and the same model in GPU instances. The results can be see in the following table:
Depending on response time requirements and other non-functional constraints, GPU usage remains a viable approach for small models. While Inferentia 2 shows some improvements in time and costs, the g6e.2xlarge instances offer comparable performance at a higher price point, with a slight advantage in response time. At this model size, the benefits of using Inferentia 2 EC2 instances are not clearly decisive.
This section describes how to perform inference in a configured EC2 Inferentia2 instance using the library neuronx-distritbuted-inference. For this section we will use the previously fine tuned Llama 8B-Instruct model.
In this section we install the necessary libraries for running inference using nxd-inference. For this, we’ll create a new virtual environment for python. Consider that the precondition for working with nxd-inference, the libraries the configurations presented in “EC2 configurations for inference in Neuron Devices” need to be installed. Execute the following code snippet for creating the virtual environment and installing the necessary python libraries:
# Create Python venv
python3.9 -m venv aws_neuron_venv_pytorch
# Activate Python venv
source aws_neuron_venv_pytorch/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscli
# Install Neuron Compiler and Framework
python -m pip install 'neuronx-cc==2.16.372.0' torch-neuronx torchvision
# Install neuronx-distributed-inference
pip install -U pip
pip install --upgrade 'neuronx-distributed-inference==0.1.1' --extra-index-url https://pip.repos.neuron.amazonaws.comThis creates a virtual environment called aws_neuron_venv_pytorch, which should be activated for running the inferences.
In this section we present the neuron configuration for the neuron model. We show the compilation and how to run the inference. First we will start by importing the necessary libraries for the following steps. We also define the folders that we are using for the default model and the neuron model:
import torch
from transformers import AutoTokenizer, GenerationConfig
from neuronx_distributed_inference.models.config import NeuronConfig
from neuronx_distributed_inference.models.llama.modeling_llama import LlamaInferenceConfig, NeuronLlamaForCausalLM
from neuronx_distributed_inference.utils.hf_adapter import HuggingFaceGenerationAdapter, load_pretrained_config
from neuronx_distributed_inference.modules.generation.sampling import prepare_sampling_params
model_path = "./voldemort-original"
traced_model_path = "./voldemort-nxd"
The following snippets create configurations for the Neuron Model. You should modify them for configurations that fit your model and your goals:
neuron_config = NeuronConfig(
tp_degree=2,
batch_size=1,
max_context_length=256,
seq_len=256,
on_device_sampling_config=None,
enable_bucketing=True,
flash_decoding_enabled=False,
dtype="bf16", # <-- Force lower precision
)
# Build the Llama Inference config
config = LlamaInferenceConfig(
neuron_config,
load_config=load_pretrained_config(model_path),
)As we are using the inf2.2xlarge for this experiment, we configure the tp_degree to the value of ‘2’. We also tested this guide in trn1.32xlarge, in that case we set the tp_degree to 32. You should set tp_degree to the number of Neuron Cores in your instance. Remember that the instances have 2 Neuron Core for each Neuron Device.
The compilation uses the configurations defined in the previous sections. For compiling we need to load the modal using the NeuronLlamaForCausalLM class and use te method .compile()
model = NeuronLlamaForCausalLM(model_path, config)
model.compile(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side="right")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.save_pretrained(traced_model_path)
In this section we will load the model and the tokenizer, preform an override of the default configurations and run the inference. For loading the model and tokenizer:
model = NeuronLlamaForCausalLM(traced_model_path)
model.load(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(traced_model_path)Here an example of how to override the default configurations for the model:
# Initialize configs
generation_config = GenerationConfig.from_pretrained(model_path)
# Some sample overrides for generation
generation_config_kwargs = {
"do_sample": True,
"top_k": 1,
}
generation_config.update(**generation_config_kwargs)For running the inference, we will define sampling params that correspond with the batch_size:
sampling_params = prepare_sampling_params(batch_size=neuron_config.batch_size,
top_k=[10],
top_p=[0.5],
temperature=[0.9])The HuggingFaceGenerationAdapter class is used for generating the inference:
prompts = [create_prompt("My Lord, what should we do with Potter?")]
inputs = tokenizer(prompts, padding=True, return_tensors="pt")
generation_model = HuggingFaceGenerationAdapter(model)
outputs = generation_model.generate(
inputs.input_ids,
generation_config=generation_config,
attention_mask=inputs.attention_mask,
max_length=model.config.neuron_config.max_length,
sampling_params=sampling_params,
)
output_tokens = tokenizer.batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print("Generated outputs:")
for i, output_token in enumerate(output_tokens):
print(f"Output {i}: {output_token}")The create_prompt function is the function for formatting the prompt and it was presented as a reference in the section “Inference using transformers-neuronx library”.
The optimum-neuron library simplifies the inference process on Neuron devices by providing an interface with minimal setup. It does not require manual compilation, allowing to quickly deploy models. However, this convenience comes with a tradeoff—Optimum-Neuron is limited to precompiled models available in the cache, restricting flexibility when working with custom architectures or models that are not officially supported.
transformers-neuronx is focused in the inference of LLMs on Neuron hardware. This makes it a more versatile choice for a wider range of LLMs models. Although compilation is required, the process is relatively straightforward.
For control and configurability, neuronx-distributed-inference offers the most advanced set of options. It allows fine-grained adjustments over inference settings. However, this level of control comes with increased complexity, making NxD-Inference more challenging to use, especially for those unfamiliar with Neuron-specific optimizations.
In terms of performance, both transformers-neuronx and nxd-Inference generally outperform Optimum-Neuron in inference speed.
Overall, the choice between these tools depends on the specific needs of the use case. optimum-neuron provides the easiest deployment option at the cost of flexibility, transformers-neuronx strikes a balance between usability and customization, and nxd-Inference offers the highest level of control and performance potential but requires deeper expertise to use effectively.
.png)



.jpg)


.jpeg)

