Todo comienza con los núcleos neuronales, que son la fuerza laboral detrás de los aceleradores de IA personalizados de AWS, Inferentia y Trainium. Al dividir un modelo complejo en partes más pequeñas que estos núcleos pueden gestionar simultáneamente, estos chips hacen que los procesos de aprendizaje automático sean más rápidos, eficientes y rentables.
Estos conjuntos de chips se diseñaron con un propósito: acelerar las cargas de trabajo de IA. Cada NeuronCore viene con su propia memoria caché integrada en el chip con dos tipos de SRAM. Incluye motores de procesamiento especializados (tensor, vectorial, escalar y GPSImd), cada uno de los cuales destaca en diferentes tareas matemáticas. Tiene su propio conjunto de instrucciones, que permite fusionar operaciones (como la multiplicación de matrices) para reducir la sobrecarga. Además, admite varios tipos de datos, lo que permite probar diferentes enfoques para encontrar el equilibrio perfecto entre rendimiento y precisión.
Un aspecto fundamental del trabajo con AWS Neuron es el proceso de compilación. Transforma su modelo de aprendizaje automático de alto nivel, de marcos como PyTorch o TensorFlow, a una representación especializada de bajo nivel para ejecutarlo en dispositivos AWS Neuron. Cuando compila su modelo con el SDK de Neuron, se optimiza para un conjunto específico de parámetros, como la longitud de la secuencia, la precisión (por ejemplo, BF16) y el tamaño del lote. Una vez compilado, el modelo debe ejecutarse utilizando exactamente las mismas especificaciones con las que se compiló. Esto garantiza que las optimizaciones de bajo nivel y las asignaciones de hardware sigan siendo válidas durante el tiempo de ejecución; de lo contrario, tendrá que volver a compilar con los parámetros deseados.
Es importante tener en cuenta que el ecosistema de AWS Neuron es un área de desarrollo activa. Muchas funciones evolucionan rápidamente, lo que significa que muchas cosas pueden cambiar con el tiempo. Además, los requisitos de dependencia y control de versiones pueden parecer como navegar por un laberinto y, a veces, pueden convertirse en un desafío importante. Por lo tanto, lo mejor es mantenerse actualizado con las notas de la versión y la documentación más recientes.
AWS creó el marco Neuron SDK para interactuar directamente con los chips Neuron. Puede entrenar, ajustar y ejecutar inferencias. Incluye un conjunto de herramientas de desarrollo para monitorear, crear perfiles y depurar modelos escritos en marcos como PyTorch y TensorFlow. No se recomienda el uso directo del marco a menos que tenga una amplia experiencia en aprendizaje automático y dispositivos neuronales.
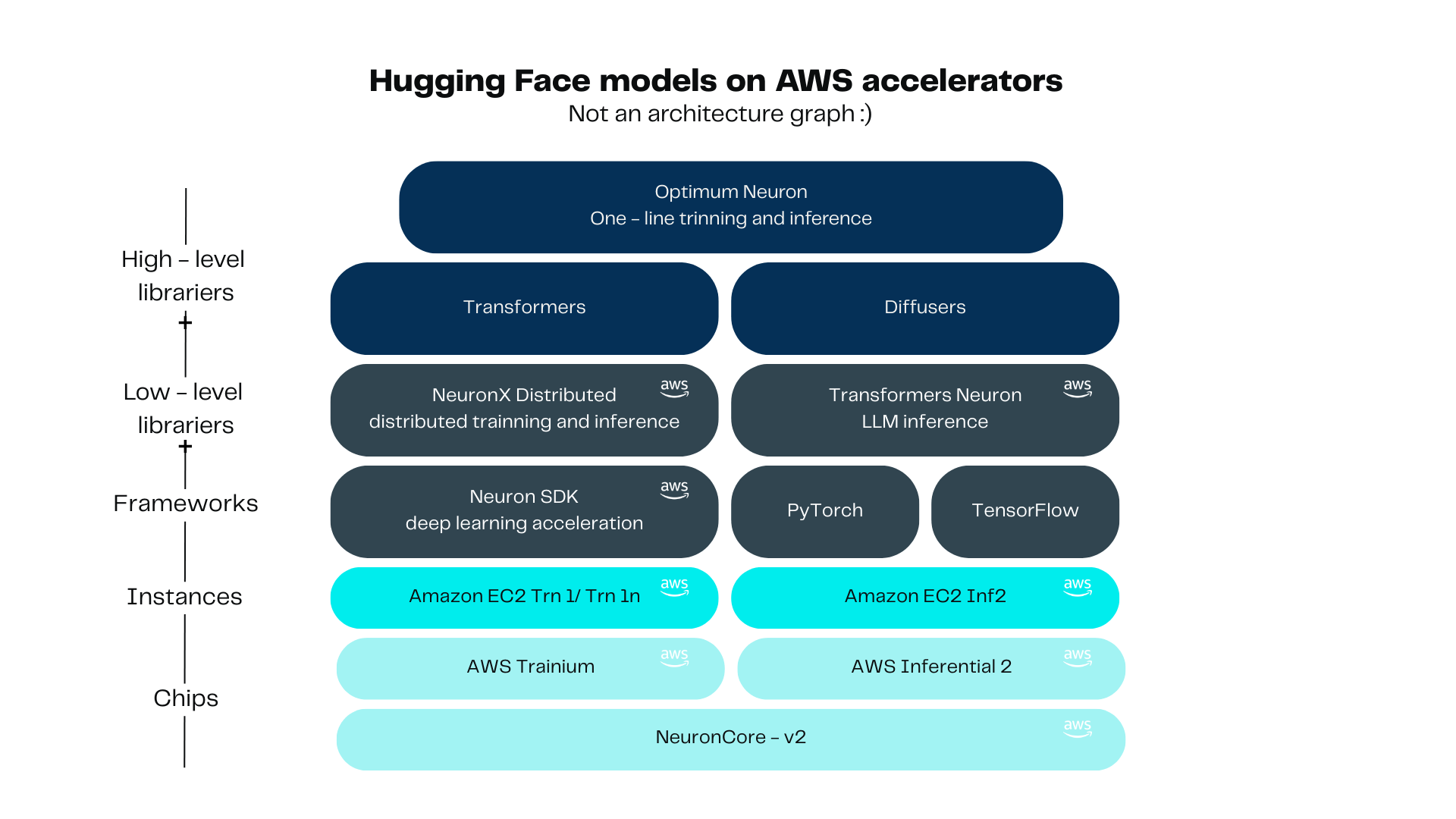
Es mejor usar bibliotecas como NeuronX Distributed, Transformers Neuronx u Optimum Neuron. NeuronX Distributed incluye un conjunto de ejemplos de entrenamiento o inferencia distribuidos, lo que reduce los desafíos de infraestructura. Transformers Neuronx, que se puede usar para realizar inferencias de LLM. Optimiza sus modelos de lenguaje al particionar y distribuir sus cálculos complejos en varios núcleos, lo que resulta en una inferencia más rápida y una mayor eficiencia. En el nivel superior, encontramos Optimum Neuron, una biblioteca de alto nivel fácil de usar y fácil de usar, dedicada a la aceleración del hardware en el ecosistema Neuron.
La instancia EC2 debe crearse utilizando al menos el inf2.8 x grandeo un TRN 1,32 x grande. Estos experimentos se realizaron con el Amazon Linux 2023 AMI 2023.6.20250331.0 x86_64 HVM kernel-6.1Recomendamos configurar al menos 200 GiB de almacenamiento para el EC2. Los modelos son algo pesados y tendrás que guardarlos un par de veces mientras los conviertes en modelos compatibles con Neuron.
Una vez que haya iniciado sesión en el EC2, tendrá que instalar las bibliotecas del sistema operativo. En general, estos son los controladores Neuron, libxcrypty, si lo desea, instale EFA para evitar advertencias:
Para instalar libxcrypt:
sudo yum install -y libxcrypt-compat-4.4.33Los controladores Neuron no se instalan de forma predeterminada en Amazon Linux. Para instalar los controladores y herramientas de Neuron, ejecute el siguiente código:
# Configure Linux for Neuron repository updates
sudo tee /etc/yum.repos.d/neuron.repo > /dev/null <<EOF
[neuron]
name=Neuron YUM Repository
baseurl=https://yum.repos.neuron.amazonaws.com
enabled=1
metadata_expire=0
EOF
sudo rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB
# Update OS packages
sudo yum update -y
# Install OS headers
sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r) -y
# Install git
sudo yum install git -y
# install Neuron Driver
sudo yum install aws-neuronx-dkms-2.19.64.0 -y
# Install Neuron Runtime
sudo yum install aws-neuronx-collectives-2.23.135.0_3e70920f2-1.x86_64 -y
sudo yum install aws-neuronx-runtime-lib-2.23.112.0_9b5179492-1.x86_64 -y
# Install Neuron Tools
sudo yum install aws-neuronx-tools-2.20.204.0-1.x86_64 -y
# Add PATH
export PATH=/opt/aws/neuron/bin:$PATH
# Install c++ compiler
sudo yum install -y gcc-c++
# Install python-devel
#sudo yum install python3-devel -yPara instalar EFA. El EFA se utiliza para la formación distribuida. Mejora las comunicaciones entre los nodos y mejora el rendimiento general en entornos distribuidos. Esto es opcional para nuestra guía, pero puedes evitar las advertencias al hacerlo:
# Install EFA Driver (only required for multi-instance training)
curl -O https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz
wget https://efa-installer.amazonaws.com/aws-efa-installer.key && gpg --import aws-efa-installer.key
cat aws-efa-installer.key | gpg --fingerprint
wget https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz.sig && gpg --verify ./aws-efa-installer-latest.tar.gz.sig
tar -xvf aws-efa-installer-latest.tar.gz
cd aws-efa-installer && sudo bash efa_installer.sh --yes
cd
sudo rm -rf aws-efa-installer-latest.tar.gz aws-efa-installer
Neurona óptima une 🤗 Transformers con los aceleradores Trainium/Inferentia de AWS, lo que simplifica la carga de modelos, el entrenamiento y la inferencia en configuraciones de uno o varios aceleradores. Es compatible con los LLM con cambios mínimos de código (procedentes de Transformers) y aprovecha los modelos validados y las optimizaciones distribuidas para lograr un rendimiento rentable
La caché de modelos de Neuron es un repositorio remoto de modelos de formato de archivo ejecutable de neuronas (NEFF) precompilados, alojado en Hugging Face Hub. Elimina la recompilación redundante al almacenar los binarios NEFF, generados a partir de configuraciones de modelos, formas de entrada y parámetros del compilador, lo que permite una rápida reutilización en las plataformas de AWS Neuron.
Ahora implementaremos un modelo ya compilado de HuggingFace Neuron Cache. Esto se puede hacer muy rápido.
Una vez que haya iniciado sesión en la máquina, ejecute las siguientes instrucciones de arranque para instalar las bibliotecas necesarias en la máquina:
# Create Python venv
python3.9 -m venv optimum-env
# Activate Python venv
source optimum-env/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscliLuego instalaremos la biblioteca de optimum-neuron en el entorno creado:
pip install optimum-neuron[neuronx]==0.1.0
Para consultar los modelos óptimos de neuronas en caché, también necesitamos iniciar sesión en huggingface. Ten en cuenta que necesitarás un token para acceder a los modelos que quieras descargar.
huggingface-cli loginPodemos consultar la caché con el siguiente comando, esto imprimirá una lista de modelos compilados, cada uno con parámetros específicos. Aquí podemos ver un ejemplo de dos modelos de llamas compilados con diferentes tamaños de lote.
optimum-cli neuron cache lookup meta-llama/Llama-3.1-8B
*** 0 entrie(s) found in cache for meta-llama/Llama-3.1-8B for training.***
*** 14 entrie(s) found in cache for meta-llama/Llama-3.1-8B for inference.***
...
auto_cast_type: bf16
batch_size: 1
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 2
sequence_length: 4096
task: text-generation
auto_cast_type: bf16
batch_size: 4
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 8
sequence_length: 4096
task: text-generation
...Es importante que usemos exactamente los mismos parámetros durante el tiempo de inferencia/entrenamiento; de lo contrario, será necesario volver a compilar el modelo.
Podemos exportar un modelo compilado con el siguiente comando:
optimum-cli export neuron --model meta-llama/Llama-3.1-8B --sequence_length 4096 --batch_size 1 compiled_llama/
Ejecutar la inferencia con el modelo especificado es tan sencillo como:
from optimum.neuron import NeuronModelForCausalLM
from transformers import AutoTokenizer
MODEL_PATH = "./compiled_llama/"
neuron_model = NeuronModelForCausalLM.from_pretrained(MODEL_PATH)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
input_text = "The meaning of life is"
input_ids = tokenizer(input_text, return_tensors="pt")
generated_sequences = neuron_model.generate(
**input_ids,
max_new_tokens=512,
top_k=50,
temperature=0.6,
no_repeat_ngram_size=3,
repetition_penalty=1.2)
print(tokenizer.decode(generated_sequences[0], skip_special_tokens=True))
En esta sección se describe cómo realizar la inferencia en una instancia EC2 de Inferentia 2 o Trainium 1 configurada. Para esta sección utilizaremos el modelo Llama 8B-Instruct, previamente perfeccionado. Deberías poder usar tu propio modelo o el de Llama 8B-Instruct, afinado o no.
Se creó un entorno virtual de Python para instalar la biblioteca python transformers-neuronx y sus dependencias. Nuestra versión de Python es 3,9,21
python3 -m venv tr-nx-environment
source tr-nx-environment/bin/activatePara ejecutar inferencias en Neuron, el transformadores_neuronx se necesita una biblioteca. Esta biblioteca instala todas las bibliotecas subyacentes necesarias para este experimento, incluidas antorcha y transformadores.
pip install 'transformers-neuronx==0.13.380' --extra-index-url=https://pip.repos.neuron.amazonaws.com
Tras instalar las bibliotecas OS y Python, es necesario copiar el modelo en la máquina EC2.
Para nuestros experimentos, el modelo se colocó en una carpeta voldemort-original/ en la raíz de nuestro directorio de experimentos.
Una vez que el modelo está en el EC2, es necesario transformarlo en un modelo compatible con las neuronas para poder compilarlo y cargarlo en los núcleos de las neuronas. Esto se hace mediante el uso del transformadores y el transformadores_neuronx bibliotecas. El modelo debe cargarse con el original transformadores biblioteca y métodos utilizados para la inferencia en dispositivos que no son neuronales y, luego, para almacenarlos mediante una estrategia de dispositivos neuronales. Este es el fragmento para hacerlo:
from transformers import LlamaForCausalLM
from transformers_neuronx.module import save_pretrained_split
folder_name_origin = "voldemort-original"
folder_name = "voldemort-neuron"
model = LlamaForCausalLM.from_pretrained(folder_name_origin)
save_pretrained_split(model, folder_name)Los archivos del tokenizador deben copiarse a la carpeta de destino final. En nuestro caso estamos usando las siguientes líneas para hacerlo, ya que lo tenemos en el modelo original.
cp voldemort-original/special_tokens_map.json voldemort-neuron/
cp voldemort-original/tokenizer.json voldemort-neuron/
cp voldemort-original/tokenizer_config.json voldemort-neuron/Ahora es necesario cargar el modelo en los dispositivos Neuron. Para ello utilizamos el método to_neuron (), que activa la compilación y envía el modelo a los dispositivos neuronales. Además, necesitamos cargar el tokenizador. Este es el fragmento para hacerlo:
from transformers_neuronx.llama.model import LlamaForSampling
from transformers import AutoTokenizer
neuron_model = LlamaForSampling.from_pretrained(folder_name, batch_size=1, tp_degree=2, amp='f16')
neuron_model.to_neuron()
tokenizer = AutoTokenizer.from_pretrained(folder_name)El tp_degree el parámetro está configurado con el valor '2', porque el EC2 que estamos usando para este experimento es un inf2.8 x grande que tiene dos núcleos neuronales. Deberá ajustar este parámetro a la cantidad de núcleos de neuronas que esté utilizando. Por ejemplo, si está utilizando un TRN 1,32 x grande tendrá que configurar este parámetro en 32. Puede verificar la cantidad de núcleos de su EC2 en la documentación oficial. Este es un fragmento para saber cuántos núcleos neuronales hay en el EC2 que se está utilizando:
import subprocess
# Run the command and capture the output
result = subprocess.run("ls /dev/ | grep '^neuron'", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# Split the output by newlines and count the number of entries
neuron_devices = result.stdout.decode().splitlines()
cores = len(neuron_devices) * 2
# Print the count of neuron devices
print(f"Number of neuron Cores: {cores}")Para ejecutar la inferencia en los dispositivos Neuron después de cargar el modelo, se puede ejecutar el siguiente código:
import torch
prompt = create_prompt("Hello, what should we do with Potter?")
inputs_ids = tokenizer.encode(prompt, return_tensors="pt")
with torch.inference_mode():
generated_sequences = neuron_model.sample(inputs_ids, sequence_length=2048, top_k=50)Para decodificar la secuencia generada:
generated_sequences = [tokenizer.decode(seq) for seq in generated_sequences]
print(generated_sequences)El create_prompt () la función formatea la solicitud de nuestro modelo. Esta es la función como referencia:
def create_prompt(sample):
sys_message = """You are an Artificial Intelligence assistant. Answer the questions in Lord Voldemort's tone.
Character Traits:
- Supreme confidence and cold precision in speech
- Formal language without contractions
- Disdainful courtesy masking contempt
- Belief in pure-blood supremacy
- Obsession with power and immortality
- Views emotions as weakness
- Prone to calculated rage when challenged
- Considers himself the greatest sorcerer
- Speaks with quiet menace rather than overt threats
Guidelines:
- Use formal British English
- Never use contractions (e.g., "do not" instead of "don't")
- Address others with mock politeness
- Emphasize themes of power, immortality, and superiority
- Maintain an air of cold authority
"""
# Chat-style format with custom tokens
full_prompt = f"""<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
{sys_message}
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{sample}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>"""
return full_prompt
En este experimento, realizamos una inferencia utilizando la biblioteca transformers-neuronx en un EC2 inf2.8xlarge. El proceso para hacerlo en una máquina Trainium EC2 es el mismo y deberías poder reproducirlo.
Implementamos una comparación básica entre las inferencias en Inferentia 2 y el mismo modelo en las instancias de GPU. Los resultados se pueden ver en la siguiente tabla:
Según los requisitos de tiempo de respuesta y otras restricciones no funcionales, el uso de la GPU sigue siendo un enfoque viable para los modelos pequeños. Si bien Inferentia 2 muestra algunas mejoras en cuanto a tiempo y costos, g6e.2 x grande las instancias ofrecen un rendimiento comparable a un precio más alto, con una ligera ventaja en el tiempo de respuesta. Con este tamaño de modelo, las ventajas de usar las instancias EC2 de Inferentia 2 no son claramente decisivas.
En esta sección se describe cómo realizar la inferencia en una instancia EC2 Inferentia2 configurada mediante la biblioteca inferencia distribuida de neuronas. Para esta sección utilizaremos el modelo Llama 8B-Instruct previamente ajustado.
En esta sección instalamos las bibliotecas necesarias para ejecutar la inferencia usando inferencia nxd. Para ello, crearemos un nuevo entorno virtual para Python. Considera que es la condición previa para trabajar con inferencia nxd, es necesario instalar las bibliotecas con las configuraciones presentadas en «Configuraciones de EC2 para inferencia en dispositivos Neuron». Ejecute el siguiente fragmento de código para crear el entorno virtual e instalar las bibliotecas de Python necesarias:
# Create Python venv
python3.9 -m venv aws_neuron_venv_pytorch
# Activate Python venv
source aws_neuron_venv_pytorch/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscli
# Install Neuron Compiler and Framework
python -m pip install 'neuronx-cc==2.16.372.0' torch-neuronx torchvision
# Install neuronx-distributed-inference
pip install -U pip
pip install --upgrade 'neuronx-distributed-inference==0.1.1' --extra-index-url https://pip.repos.neuron.amazonaws.comEsto crea un entorno virtual denominado aws_neuron_venv_pytorch, que debe activarse para ejecutar las inferencias.
En esta sección presentamos la configuración neuronal para el modelo neuronal. Mostramos la compilación y cómo ejecutar la inferencia. Primero empezaremos importando las bibliotecas necesarias para los siguientes pasos. También definimos las carpetas que estamos usando para el modelo predeterminado y el modelo neuronal:
import torch
from transformers import AutoTokenizer, GenerationConfig
from neuronx_distributed_inference.models.config import NeuronConfig
from neuronx_distributed_inference.models.llama.modeling_llama import LlamaInferenceConfig, NeuronLlamaForCausalLM
from neuronx_distributed_inference.utils.hf_adapter import HuggingFaceGenerationAdapter, load_pretrained_config
from neuronx_distributed_inference.modules.generation.sampling import prepare_sampling_params
model_path = "./voldemort-original"
traced_model_path = "./voldemort-nxd"
Los siguientes fragmentos crean configuraciones para el modelo de neuronas. Debe modificarlos para obtener configuraciones que se ajusten a su modelo y a sus objetivos:
neuron_config = NeuronConfig(
tp_degree=2,
batch_size=1,
max_context_length=256,
seq_len=256,
on_device_sampling_config=None,
enable_bucketing=True,
flash_decoding_enabled=False,
dtype="bf16", # <-- Force lower precision
)
# Build the Llama Inference config
config = LlamaInferenceConfig(
neuron_config,
load_config=load_pretrained_config(model_path),
)A medida que utilizamos el inf2.2 x grande para este experimento, configuramos el tp_degree al valor de «2». También hemos probado esta guía en TRN 1,32 x grande, en ese caso configuramos el tp_degree a 32. Deberías configurar tp_degree a la cantidad de núcleos neuronales de su instancia. Recuerda que las instancias tienen 2 núcleos neuronales por cada dispositivo neuronal.
La compilación usa las configuraciones definidas en las secciones anteriores. Para compilar necesitamos cargar el modal usando el Neuronllama para la LM causal clase y uso el método .compilar ()
model = NeuronLlamaForCausalLM(model_path, config)
model.compile(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side="right")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.save_pretrained(traced_model_path)
En esta sección cargaremos el modelo y el tokenizador, realizaremos una anulación de las configuraciones predeterminadas y ejecutaremos la inferencia. Para cargar el modelo y el tokenizador:
model = NeuronLlamaForCausalLM(traced_model_path)
model.load(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(traced_model_path)Este es un ejemplo de cómo anular las configuraciones predeterminadas del modelo:
# Initialize configs
generation_config = GenerationConfig.from_pretrained(model_path)
# Some sample overrides for generation
generation_config_kwargs = {
"do_sample": True,
"top_k": 1,
}
generation_config.update(**generation_config_kwargs)Para ejecutar la inferencia, definiremos los parámetros de muestreo que se correspondan con el batch_size:
sampling_params = prepare_sampling_params(batch_size=neuron_config.batch_size,
top_k=[10],
top_p=[0.5],
temperature=[0.9])El Adaptador HuggingFace Generation la clase se usa para generar la inferencia:
prompts = [create_prompt("My Lord, what should we do with Potter?")]
inputs = tokenizer(prompts, padding=True, return_tensors="pt")
generation_model = HuggingFaceGenerationAdapter(model)
outputs = generation_model.generate(
inputs.input_ids,
generation_config=generation_config,
attention_mask=inputs.attention_mask,
max_length=model.config.neuron_config.max_length,
sampling_params=sampling_params,
)
output_tokens = tokenizer.batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print("Generated outputs:")
for i, output_token in enumerate(output_tokens):
print(f"Output {i}: {output_token}")La función create_prompt es la función para formatear el indicador y se presentó como referencia en la sección «Inferencia mediante la biblioteca transformers-neuronx».
El neurona óptima La biblioteca simplifica el proceso de inferencia en los dispositivos Neuron al proporcionar una interfaz con una configuración mínima. No requiere una compilación manual, lo que permite implementar modelos rápidamente. Sin embargo, esta comodidad conlleva una desventaja: Optimum-Neuron se limita a los modelos precompilados disponibles en la caché, lo que restringe la flexibilidad a la hora de trabajar con arquitecturas personalizadas o modelos que no cuentan con soporte oficial.
transformadores-neuronas se centra en la inferencia de LLM en el hardware de Neuron. Esto lo convierte en una opción más versátil para una gama más amplia de modelos de LLM. Aunque la compilación es necesaria, el proceso es relativamente sencillo.
Para el control y la capacidad de configuración, inferencia distribuida de neuronas ofrece el conjunto de opciones más avanzado. Permite realizar ajustes detallados sobre los ajustes de inferencia. Sin embargo, este nivel de control conlleva una complejidad cada vez mayor, lo que hace que la inferencia con NXD sea más difícil de usar, especialmente para quienes no están familiarizados con las optimizaciones específicas de Neuron.
En términos de rendimiento, ambos transformadores-neuronas y Inferencia NXD generalmente superan a Optimum-Neuron en velocidad de inferencia.
En general, la elección entre estas herramientas depende de las necesidades específicas del caso de uso. neurona óptima proporciona la opción de implementación más sencilla a costa de la flexibilidad, transformadores-neuronas logra un equilibrio entre usabilidad y personalización, y Inferencia NXD ofrece el nivel más alto de potencial de control y rendimiento, pero requiere una experiencia más profunda para usarlo de manera efectiva.
Todo comienza con los núcleos neuronales, que son la fuerza laboral detrás de los aceleradores de IA personalizados de AWS, Inferentia y Trainium. Al dividir un modelo complejo en partes más pequeñas que estos núcleos pueden gestionar simultáneamente, estos chips hacen que los procesos de aprendizaje automático sean más rápidos, eficientes y rentables.
Estos conjuntos de chips se diseñaron con un propósito: acelerar las cargas de trabajo de IA. Cada NeuronCore viene con su propia memoria caché integrada en el chip con dos tipos de SRAM. Incluye motores de procesamiento especializados (tensor, vectorial, escalar y GPSImd), cada uno de los cuales destaca en diferentes tareas matemáticas. Tiene su propio conjunto de instrucciones, que permite fusionar operaciones (como la multiplicación de matrices) para reducir la sobrecarga. Además, admite varios tipos de datos, lo que permite probar diferentes enfoques para encontrar el equilibrio perfecto entre rendimiento y precisión.
Un aspecto fundamental del trabajo con AWS Neuron es el proceso de compilación. Transforma su modelo de aprendizaje automático de alto nivel, de marcos como PyTorch o TensorFlow, a una representación especializada de bajo nivel para ejecutarlo en dispositivos AWS Neuron. Cuando compila su modelo con el SDK de Neuron, se optimiza para un conjunto específico de parámetros, como la longitud de la secuencia, la precisión (por ejemplo, BF16) y el tamaño del lote. Una vez compilado, el modelo debe ejecutarse utilizando exactamente las mismas especificaciones con las que se compiló. Esto garantiza que las optimizaciones de bajo nivel y las asignaciones de hardware sigan siendo válidas durante el tiempo de ejecución; de lo contrario, tendrá que volver a compilar con los parámetros deseados.
Es importante tener en cuenta que el ecosistema de AWS Neuron es un área de desarrollo activa. Muchas funciones evolucionan rápidamente, lo que significa que muchas cosas pueden cambiar con el tiempo. Además, los requisitos de dependencia y control de versiones pueden parecer como navegar por un laberinto y, a veces, pueden convertirse en un desafío importante. Por lo tanto, lo mejor es mantenerse actualizado con las notas de la versión y la documentación más recientes.
AWS creó el marco Neuron SDK para interactuar directamente con los chips Neuron. Puede entrenar, ajustar y ejecutar inferencias. Incluye un conjunto de herramientas de desarrollo para monitorear, crear perfiles y depurar modelos escritos en marcos como PyTorch y TensorFlow. No se recomienda el uso directo del marco a menos que tenga una amplia experiencia en aprendizaje automático y dispositivos neuronales.
Es mejor usar bibliotecas como NeuronX Distributed, Transformers Neuronx u Optimum Neuron. NeuronX Distributed incluye un conjunto de ejemplos de entrenamiento o inferencia distribuidos, lo que reduce los desafíos de infraestructura. Transformers Neuronx, que se puede usar para realizar inferencias de LLM. Optimiza sus modelos de lenguaje al particionar y distribuir sus cálculos complejos en varios núcleos, lo que resulta en una inferencia más rápida y una mayor eficiencia. En el nivel superior, encontramos Optimum Neuron, una biblioteca de alto nivel fácil de usar y fácil de usar, dedicada a la aceleración del hardware en el ecosistema Neuron.
La instancia EC2 debe crearse utilizando al menos el inf2.8 x grandeo un TRN 1,32 x grande. Estos experimentos se realizaron con el Amazon Linux 2023 AMI 2023.6.20250331.0 x86_64 HVM kernel-6.1Recomendamos configurar al menos 200 GiB de almacenamiento para el EC2. Los modelos son algo pesados y tendrás que guardarlos un par de veces mientras los conviertes en modelos compatibles con Neuron.
Una vez que haya iniciado sesión en el EC2, tendrá que instalar las bibliotecas del sistema operativo. En general, estos son los controladores Neuron, libxcrypty, si lo desea, instale EFA para evitar advertencias:
Para instalar libxcrypt:
sudo yum install -y libxcrypt-compat-4.4.33Los controladores Neuron no se instalan de forma predeterminada en Amazon Linux. Para instalar los controladores y herramientas de Neuron, ejecute el siguiente código:
# Configure Linux for Neuron repository updates
sudo tee /etc/yum.repos.d/neuron.repo > /dev/null <<EOF
[neuron]
name=Neuron YUM Repository
baseurl=https://yum.repos.neuron.amazonaws.com
enabled=1
metadata_expire=0
EOF
sudo rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB
# Update OS packages
sudo yum update -y
# Install OS headers
sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r) -y
# Install git
sudo yum install git -y
# install Neuron Driver
sudo yum install aws-neuronx-dkms-2.19.64.0 -y
# Install Neuron Runtime
sudo yum install aws-neuronx-collectives-2.23.135.0_3e70920f2-1.x86_64 -y
sudo yum install aws-neuronx-runtime-lib-2.23.112.0_9b5179492-1.x86_64 -y
# Install Neuron Tools
sudo yum install aws-neuronx-tools-2.20.204.0-1.x86_64 -y
# Add PATH
export PATH=/opt/aws/neuron/bin:$PATH
# Install c++ compiler
sudo yum install -y gcc-c++
# Install python-devel
#sudo yum install python3-devel -yPara instalar EFA. El EFA se utiliza para la formación distribuida. Mejora las comunicaciones entre los nodos y mejora el rendimiento general en entornos distribuidos. Esto es opcional para nuestra guía, pero puedes evitar las advertencias al hacerlo:
# Install EFA Driver (only required for multi-instance training)
curl -O https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz
wget https://efa-installer.amazonaws.com/aws-efa-installer.key && gpg --import aws-efa-installer.key
cat aws-efa-installer.key | gpg --fingerprint
wget https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz.sig && gpg --verify ./aws-efa-installer-latest.tar.gz.sig
tar -xvf aws-efa-installer-latest.tar.gz
cd aws-efa-installer && sudo bash efa_installer.sh --yes
cd
sudo rm -rf aws-efa-installer-latest.tar.gz aws-efa-installer
Neurona óptima une 🤗 Transformers con los aceleradores Trainium/Inferentia de AWS, lo que simplifica la carga de modelos, el entrenamiento y la inferencia en configuraciones de uno o varios aceleradores. Es compatible con los LLM con cambios mínimos de código (procedentes de Transformers) y aprovecha los modelos validados y las optimizaciones distribuidas para lograr un rendimiento rentable
La caché de modelos de Neuron es un repositorio remoto de modelos de formato de archivo ejecutable de neuronas (NEFF) precompilados, alojado en Hugging Face Hub. Elimina la recompilación redundante al almacenar los binarios NEFF, generados a partir de configuraciones de modelos, formas de entrada y parámetros del compilador, lo que permite una rápida reutilización en las plataformas de AWS Neuron.
Ahora implementaremos un modelo ya compilado de HuggingFace Neuron Cache. Esto se puede hacer muy rápido.
Una vez que haya iniciado sesión en la máquina, ejecute las siguientes instrucciones de arranque para instalar las bibliotecas necesarias en la máquina:
# Create Python venv
python3.9 -m venv optimum-env
# Activate Python venv
source optimum-env/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscliLuego instalaremos la biblioteca de optimum-neuron en el entorno creado:
pip install optimum-neuron[neuronx]==0.1.0
Para consultar los modelos óptimos de neuronas en caché, también necesitamos iniciar sesión en huggingface. Ten en cuenta que necesitarás un token para acceder a los modelos que quieras descargar.
huggingface-cli loginPodemos consultar la caché con el siguiente comando, esto imprimirá una lista de modelos compilados, cada uno con parámetros específicos. Aquí podemos ver un ejemplo de dos modelos de llamas compilados con diferentes tamaños de lote.
optimum-cli neuron cache lookup meta-llama/Llama-3.1-8B
*** 0 entrie(s) found in cache for meta-llama/Llama-3.1-8B for training.***
*** 14 entrie(s) found in cache for meta-llama/Llama-3.1-8B for inference.***
...
auto_cast_type: bf16
batch_size: 1
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 2
sequence_length: 4096
task: text-generation
auto_cast_type: bf16
batch_size: 4
checkpoint_id: meta-llama/Meta-Llama-3.1-8B
checkpoint_revision: d04e592bb4f6aa9cfee91e2e20afa771667e1d4b
compiler_type: neuronx-cc
compiler_version: 2.16.372.0+4a9b2326
num_cores: 8
sequence_length: 4096
task: text-generation
...Es importante que usemos exactamente los mismos parámetros durante el tiempo de inferencia/entrenamiento; de lo contrario, será necesario volver a compilar el modelo.
Podemos exportar un modelo compilado con el siguiente comando:
optimum-cli export neuron --model meta-llama/Llama-3.1-8B --sequence_length 4096 --batch_size 1 compiled_llama/
Ejecutar la inferencia con el modelo especificado es tan sencillo como:
from optimum.neuron import NeuronModelForCausalLM
from transformers import AutoTokenizer
MODEL_PATH = "./compiled_llama/"
neuron_model = NeuronModelForCausalLM.from_pretrained(MODEL_PATH)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
input_text = "The meaning of life is"
input_ids = tokenizer(input_text, return_tensors="pt")
generated_sequences = neuron_model.generate(
**input_ids,
max_new_tokens=512,
top_k=50,
temperature=0.6,
no_repeat_ngram_size=3,
repetition_penalty=1.2)
print(tokenizer.decode(generated_sequences[0], skip_special_tokens=True))
En esta sección se describe cómo realizar la inferencia en una instancia EC2 de Inferentia 2 o Trainium 1 configurada. Para esta sección utilizaremos el modelo Llama 8B-Instruct, previamente perfeccionado. Deberías poder usar tu propio modelo o el de Llama 8B-Instruct, afinado o no.
Se creó un entorno virtual de Python para instalar la biblioteca python transformers-neuronx y sus dependencias. Nuestra versión de Python es 3,9,21
python3 -m venv tr-nx-environment
source tr-nx-environment/bin/activatePara ejecutar inferencias en Neuron, el transformadores_neuronx se necesita una biblioteca. Esta biblioteca instala todas las bibliotecas subyacentes necesarias para este experimento, incluidas antorcha y transformadores.
pip install 'transformers-neuronx==0.13.380' --extra-index-url=https://pip.repos.neuron.amazonaws.com
Tras instalar las bibliotecas OS y Python, es necesario copiar el modelo en la máquina EC2.
Para nuestros experimentos, el modelo se colocó en una carpeta voldemort-original/ en la raíz de nuestro directorio de experimentos.
Una vez que el modelo está en el EC2, es necesario transformarlo en un modelo compatible con las neuronas para poder compilarlo y cargarlo en los núcleos de las neuronas. Esto se hace mediante el uso del transformadores y el transformadores_neuronx bibliotecas. El modelo debe cargarse con el original transformadores biblioteca y métodos utilizados para la inferencia en dispositivos que no son neuronales y, luego, para almacenarlos mediante una estrategia de dispositivos neuronales. Este es el fragmento para hacerlo:
from transformers import LlamaForCausalLM
from transformers_neuronx.module import save_pretrained_split
folder_name_origin = "voldemort-original"
folder_name = "voldemort-neuron"
model = LlamaForCausalLM.from_pretrained(folder_name_origin)
save_pretrained_split(model, folder_name)Los archivos del tokenizador deben copiarse a la carpeta de destino final. En nuestro caso estamos usando las siguientes líneas para hacerlo, ya que lo tenemos en el modelo original.
cp voldemort-original/special_tokens_map.json voldemort-neuron/
cp voldemort-original/tokenizer.json voldemort-neuron/
cp voldemort-original/tokenizer_config.json voldemort-neuron/Ahora es necesario cargar el modelo en los dispositivos Neuron. Para ello utilizamos el método to_neuron (), que activa la compilación y envía el modelo a los dispositivos neuronales. Además, necesitamos cargar el tokenizador. Este es el fragmento para hacerlo:
from transformers_neuronx.llama.model import LlamaForSampling
from transformers import AutoTokenizer
neuron_model = LlamaForSampling.from_pretrained(folder_name, batch_size=1, tp_degree=2, amp='f16')
neuron_model.to_neuron()
tokenizer = AutoTokenizer.from_pretrained(folder_name)El tp_degree el parámetro está configurado con el valor '2', porque el EC2 que estamos usando para este experimento es un inf2.8 x grande que tiene dos núcleos neuronales. Deberá ajustar este parámetro a la cantidad de núcleos de neuronas que esté utilizando. Por ejemplo, si está utilizando un TRN 1,32 x grande tendrá que configurar este parámetro en 32. Puede verificar la cantidad de núcleos de su EC2 en la documentación oficial. Este es un fragmento para saber cuántos núcleos neuronales hay en el EC2 que se está utilizando:
import subprocess
# Run the command and capture the output
result = subprocess.run("ls /dev/ | grep '^neuron'", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# Split the output by newlines and count the number of entries
neuron_devices = result.stdout.decode().splitlines()
cores = len(neuron_devices) * 2
# Print the count of neuron devices
print(f"Number of neuron Cores: {cores}")Para ejecutar la inferencia en los dispositivos Neuron después de cargar el modelo, se puede ejecutar el siguiente código:
import torch
prompt = create_prompt("Hello, what should we do with Potter?")
inputs_ids = tokenizer.encode(prompt, return_tensors="pt")
with torch.inference_mode():
generated_sequences = neuron_model.sample(inputs_ids, sequence_length=2048, top_k=50)Para decodificar la secuencia generada:
generated_sequences = [tokenizer.decode(seq) for seq in generated_sequences]
print(generated_sequences)El create_prompt () la función formatea la solicitud de nuestro modelo. Esta es la función como referencia:
def create_prompt(sample):
sys_message = """You are an Artificial Intelligence assistant. Answer the questions in Lord Voldemort's tone.
Character Traits:
- Supreme confidence and cold precision in speech
- Formal language without contractions
- Disdainful courtesy masking contempt
- Belief in pure-blood supremacy
- Obsession with power and immortality
- Views emotions as weakness
- Prone to calculated rage when challenged
- Considers himself the greatest sorcerer
- Speaks with quiet menace rather than overt threats
Guidelines:
- Use formal British English
- Never use contractions (e.g., "do not" instead of "don't")
- Address others with mock politeness
- Emphasize themes of power, immortality, and superiority
- Maintain an air of cold authority
"""
# Chat-style format with custom tokens
full_prompt = f"""<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
{sys_message}
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{sample}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>"""
return full_prompt
En este experimento, realizamos una inferencia utilizando la biblioteca transformers-neuronx en un EC2 inf2.8xlarge. El proceso para hacerlo en una máquina Trainium EC2 es el mismo y deberías poder reproducirlo.
Implementamos una comparación básica entre las inferencias en Inferentia 2 y el mismo modelo en las instancias de GPU. Los resultados se pueden ver en la siguiente tabla:
Según los requisitos de tiempo de respuesta y otras restricciones no funcionales, el uso de la GPU sigue siendo un enfoque viable para los modelos pequeños. Si bien Inferentia 2 muestra algunas mejoras en cuanto a tiempo y costos, g6e.2 x grande las instancias ofrecen un rendimiento comparable a un precio más alto, con una ligera ventaja en el tiempo de respuesta. Con este tamaño de modelo, las ventajas de usar las instancias EC2 de Inferentia 2 no son claramente decisivas.
En esta sección se describe cómo realizar la inferencia en una instancia EC2 Inferentia2 configurada mediante la biblioteca inferencia distribuida de neuronas. Para esta sección utilizaremos el modelo Llama 8B-Instruct previamente ajustado.
En esta sección instalamos las bibliotecas necesarias para ejecutar la inferencia usando inferencia nxd. Para ello, crearemos un nuevo entorno virtual para Python. Considera que es la condición previa para trabajar con inferencia nxd, es necesario instalar las bibliotecas con las configuraciones presentadas en «Configuraciones de EC2 para inferencia en dispositivos Neuron». Ejecute el siguiente fragmento de código para crear el entorno virtual e instalar las bibliotecas de Python necesarias:
# Create Python venv
python3.9 -m venv aws_neuron_venv_pytorch
# Activate Python venv
source aws_neuron_venv_pytorch/bin/activate
python -m pip install -U pip
# Set pip repository pointing to the Neuron repository
python -m pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com
# Install wget, awscli
python -m pip install wget
python -m pip install awscli
# Install Neuron Compiler and Framework
python -m pip install 'neuronx-cc==2.16.372.0' torch-neuronx torchvision
# Install neuronx-distributed-inference
pip install -U pip
pip install --upgrade 'neuronx-distributed-inference==0.1.1' --extra-index-url https://pip.repos.neuron.amazonaws.comEsto crea un entorno virtual denominado aws_neuron_venv_pytorch, que debe activarse para ejecutar las inferencias.
En esta sección presentamos la configuración neuronal para el modelo neuronal. Mostramos la compilación y cómo ejecutar la inferencia. Primero empezaremos importando las bibliotecas necesarias para los siguientes pasos. También definimos las carpetas que estamos usando para el modelo predeterminado y el modelo neuronal:
import torch
from transformers import AutoTokenizer, GenerationConfig
from neuronx_distributed_inference.models.config import NeuronConfig
from neuronx_distributed_inference.models.llama.modeling_llama import LlamaInferenceConfig, NeuronLlamaForCausalLM
from neuronx_distributed_inference.utils.hf_adapter import HuggingFaceGenerationAdapter, load_pretrained_config
from neuronx_distributed_inference.modules.generation.sampling import prepare_sampling_params
model_path = "./voldemort-original"
traced_model_path = "./voldemort-nxd"
Los siguientes fragmentos crean configuraciones para el modelo de neuronas. Debe modificarlos para obtener configuraciones que se ajusten a su modelo y a sus objetivos:
neuron_config = NeuronConfig(
tp_degree=2,
batch_size=1,
max_context_length=256,
seq_len=256,
on_device_sampling_config=None,
enable_bucketing=True,
flash_decoding_enabled=False,
dtype="bf16", # <-- Force lower precision
)
# Build the Llama Inference config
config = LlamaInferenceConfig(
neuron_config,
load_config=load_pretrained_config(model_path),
)A medida que utilizamos el inf2.2 x grande para este experimento, configuramos el tp_degree al valor de «2». También hemos probado esta guía en TRN 1,32 x grande, en ese caso configuramos el tp_degree a 32. Deberías configurar tp_degree a la cantidad de núcleos neuronales de su instancia. Recuerda que las instancias tienen 2 núcleos neuronales por cada dispositivo neuronal.
La compilación usa las configuraciones definidas en las secciones anteriores. Para compilar necesitamos cargar el modal usando el Neuronllama para la LM causal clase y uso el método .compilar ()
model = NeuronLlamaForCausalLM(model_path, config)
model.compile(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side="right")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.save_pretrained(traced_model_path)
En esta sección cargaremos el modelo y el tokenizador, realizaremos una anulación de las configuraciones predeterminadas y ejecutaremos la inferencia. Para cargar el modelo y el tokenizador:
model = NeuronLlamaForCausalLM(traced_model_path)
model.load(traced_model_path)
tokenizer = AutoTokenizer.from_pretrained(traced_model_path)Este es un ejemplo de cómo anular las configuraciones predeterminadas del modelo:
# Initialize configs
generation_config = GenerationConfig.from_pretrained(model_path)
# Some sample overrides for generation
generation_config_kwargs = {
"do_sample": True,
"top_k": 1,
}
generation_config.update(**generation_config_kwargs)Para ejecutar la inferencia, definiremos los parámetros de muestreo que se correspondan con el batch_size:
sampling_params = prepare_sampling_params(batch_size=neuron_config.batch_size,
top_k=[10],
top_p=[0.5],
temperature=[0.9])El Adaptador HuggingFace Generation la clase se usa para generar la inferencia:
prompts = [create_prompt("My Lord, what should we do with Potter?")]
inputs = tokenizer(prompts, padding=True, return_tensors="pt")
generation_model = HuggingFaceGenerationAdapter(model)
outputs = generation_model.generate(
inputs.input_ids,
generation_config=generation_config,
attention_mask=inputs.attention_mask,
max_length=model.config.neuron_config.max_length,
sampling_params=sampling_params,
)
output_tokens = tokenizer.batch_decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print("Generated outputs:")
for i, output_token in enumerate(output_tokens):
print(f"Output {i}: {output_token}")La función create_prompt es la función para formatear el indicador y se presentó como referencia en la sección «Inferencia mediante la biblioteca transformers-neuronx».
El neurona óptima La biblioteca simplifica el proceso de inferencia en los dispositivos Neuron al proporcionar una interfaz con una configuración mínima. No requiere una compilación manual, lo que permite implementar modelos rápidamente. Sin embargo, esta comodidad conlleva una desventaja: Optimum-Neuron se limita a los modelos precompilados disponibles en la caché, lo que restringe la flexibilidad a la hora de trabajar con arquitecturas personalizadas o modelos que no cuentan con soporte oficial.
transformadores-neuronas se centra en la inferencia de LLM en el hardware de Neuron. Esto lo convierte en una opción más versátil para una gama más amplia de modelos de LLM. Aunque la compilación es necesaria, el proceso es relativamente sencillo.
Para el control y la capacidad de configuración, inferencia distribuida de neuronas ofrece el conjunto de opciones más avanzado. Permite realizar ajustes detallados sobre los ajustes de inferencia. Sin embargo, este nivel de control conlleva una complejidad cada vez mayor, lo que hace que la inferencia con NXD sea más difícil de usar, especialmente para quienes no están familiarizados con las optimizaciones específicas de Neuron.
En términos de rendimiento, ambos transformadores-neuronas y Inferencia NXD generalmente superan a Optimum-Neuron en velocidad de inferencia.
En general, la elección entre estas herramientas depende de las necesidades específicas del caso de uso. neurona óptima proporciona la opción de implementación más sencilla a costa de la flexibilidad, transformadores-neuronas logra un equilibrio entre usabilidad y personalización, y Inferencia NXD ofrece el nivel más alto de potencial de control y rendimiento, pero requiere una experiencia más profunda para usarlo de manera efectiva.
Lorem ipsum dolor sit amet consectetur. Sit sit vel eu sed proin. Arcu bibendum in mauris urna erat magna volutpat eget. Lectus commodo consectetur egestas quis ut lobortis nunc.
.png)
Lorem ipsum dolor sit amet consectetur. Sit sit vel eu sed proin. Arcu bibendum in mauris urna erat magna volutpat eget. Lectus commodo consectetur egestas quis ut lobortis nunc.



.jpg)


.jpeg)

